The Thundering Herd Problem: Causes, Effects, and Solutions
In the world of distributed systems, scalability, and high availability; one of the most notorious challenges is the Thundering Herd Problem. This issue can cripple even the most robust systems if not addressed properly.

Introduction
In the world of distributed systems, scalability, and high availability; one of the most notorious challenges is the Thundering Herd Problem. This issue can cripple even the most robust systems if not addressed properly. In this blog post, we’ll explore the definition, causes, effects, and real-world examples of the Thundering Herd Problem, along with practical solutions to mitigate it.
What is the Thundering Herd Problem?
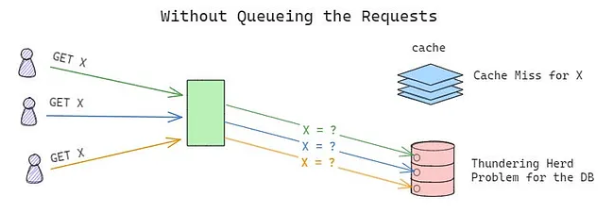
The Thundering Herd Problem occurs when a large number of concurrent requests or processes simultaneously attempt to access a shared resource. This sudden surge in demand overwhelms the system, leading to performance degradation, increased latency, and even system crashes.
This problem is particularly common in distributed systems, APIs, and caching mechanisms, where multiple clients or processes depend on the same resource. For example, a cache miss for a popular item can trigger a flood of requests to the backend database, overwhelming it and causing cascading failures.
Causes of the Thundering Herd Problem
The Thundering Herd Problem is often triggered by specific patterns of system behavior or design flaws. Here are the most common causes:
- Sudden Spikes in Concurrent Requests:
- A large number of clients or processes simultaneously request access to a shared resource. This can happen during events like flash sales, breaking news, or system restarts.
- Resource Contention:
- Multiple processes compete for access to a limited resource, such as a database, API, or cache. This contention creates bottlenecks and delays.
- Retry Storms:
- When requests fail due to resource unavailability, clients often retry simultaneously. This synchronized retry behavior amplifies the load on the system, worsening the problem.
- Cache Misses:
- In caching systems, a cache miss for a popular item can result in all requests being forwarded to the backend datastore, creating a bottleneck.
- Autoscaling Delays:
- Autoscaling mechanisms often take time to detect spikes and provision additional resources. During this delay, the existing infrastructure may become overwhelmed.
- Unpredictable Traffic Patterns:
- Systems that experience sudden, unpredictable surges in traffic (e.g., payment gateways, ticketing systems) are particularly vulnerable.
Effects of the Thundering Herd Problem
The Thundering Herd Problem can have severe consequences for system performance, user experience, and operational stability. Here are the key effects:
Increased Latency
- Resource Contention: When multiple clients compete for the same resource, requests are queued, leading to delays.
- Server Response Time: High request loads slow down server responses, especially after downtime or maintenance.
System Overload
- Servers bombarded with requests may crash or become unresponsive.
- Overload leads to service interruptions and cascading failures as retries combine with new incoming requests.
Resource Starvation
- Depletion: Shared resources are quickly exhausted, impacting availability.
- Unfair Allocation: Some clients monopolize resources, leaving others underserved.
Scaling Challenges
- Operational Complexity: Scaling up resources quickly during a surge is difficult and costly.
- Resource Fragmentation: Repeated surges lead to inefficient resource allocation.
Cascading Failures
- When one part of the system fails, it can trigger a chain reaction, causing other components to fail as well. For example, a database crash can lead to API failures, which in turn cause retries that further overload the system.
Real-World Example: PayPal’s Thundering Herd Problem
In 2018, PayPal’s Braintree payment gateway faced a classic Thundering Herd Problem with its Disputes API. This API, used by merchants to manage chargebacks, experienced unpredictable traffic spikes. Despite autoscaling, the system struggled with:
- Retry Storms: Failed jobs retried at static intervals, compounding the load.
- Cascading Failures: Processor services were overwhelmed by queued jobs and retries.
Challenges Faced
- Lag in Autoscaling: Autoscaling took 45+ seconds to respond to spikes, during which existing servers were overwhelmed.
- Resource Constraints: New nodes were not provisioned quickly enough.
- Short-Lived Spikes: Brief traffic surges were not captured by monitoring systems.
Solutions Implemented
- Exponential Backoff: Introduced increasing delays between retries to reduce contention.
- Exponential Backoff with Jitter: Added randomness to retry intervals, spreading out the load and preventing synchronized retries.
Solutions to the Thundering Herd Problem
Addressing the Thundering Herd Problem requires a combination of strategies tailored to the specific system and workload. Here are some of the most effective solutions:
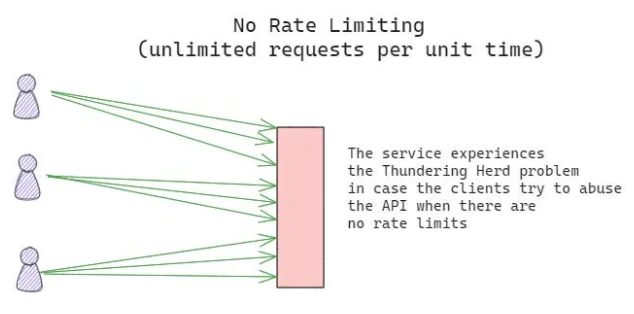
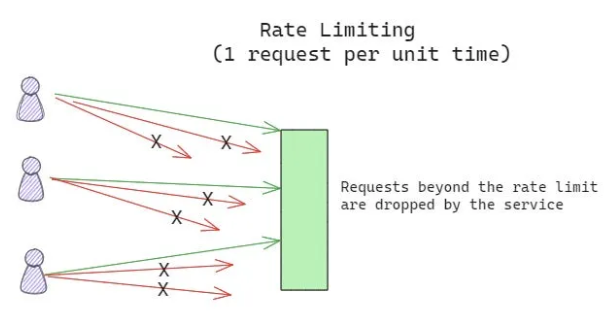
Rate Limiting
- What It Does: Controls how frequently clients can make requests to an API or service.
- Use Case: Prevents abuse during traffic spikes, such as DDoS attacks or batch jobs.
- Implementation: Limit the number of requests per client over a specific time window (e.g., 100 requests per minute).
Concurrent Request Limiting
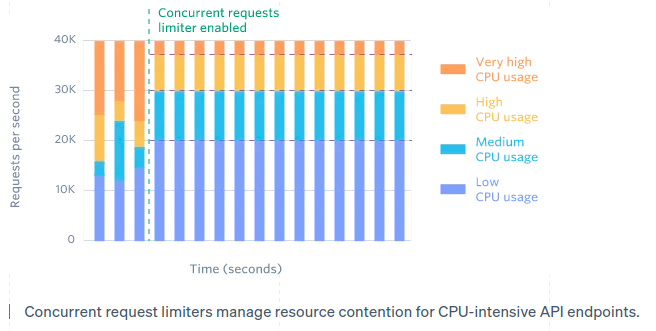
- What It Does: Restricts the number of concurrent requests processed at any given time.
- How It Works:
- Distribute load evenly across workers.
- Prioritize less resource-intensive tasks to prevent contention.
- Example: Allow only 10 concurrent API requests per client, queuing the rest.
Load Shedding
- Fleet Usage Load Shedding:
- Reserve a portion of infrastructure (e.g., 20%) for critical requests.
- Reject non-critical requests exceeding their allocated capacity with a 503 status code.

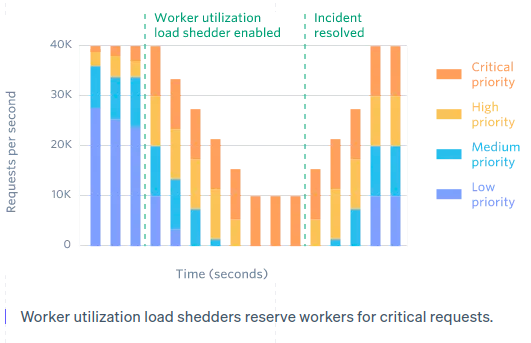
- Worker Utilization Load Shedding
- Categorize traffic into priority levels (e.g., critical, high, medium, low).
- Gradually shed lower-priority requests during overload until the system recovers.
- Example: If critical requests exceed capacity, lower-priority requests are dropped first.
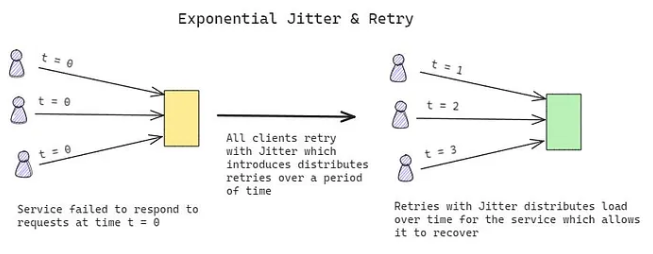
Exponential Backoff with Jitter
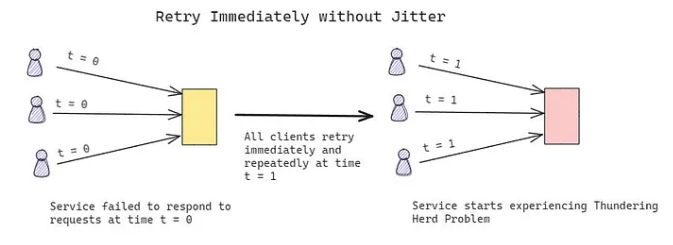
- Exponential Backoff:
- Introduce increasing wait times between retries to reduce contention.
- Formula: Retry Time = Base * 2^Retry Count
- Example: Retry 1 = 200ms, Retry 2 = 400ms, Retry 3 = 800ms.
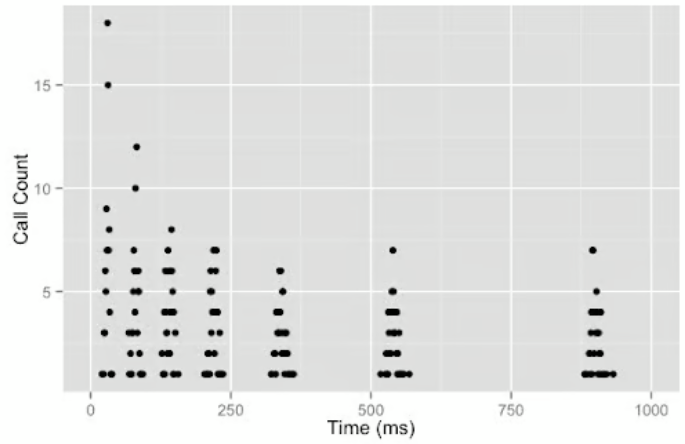
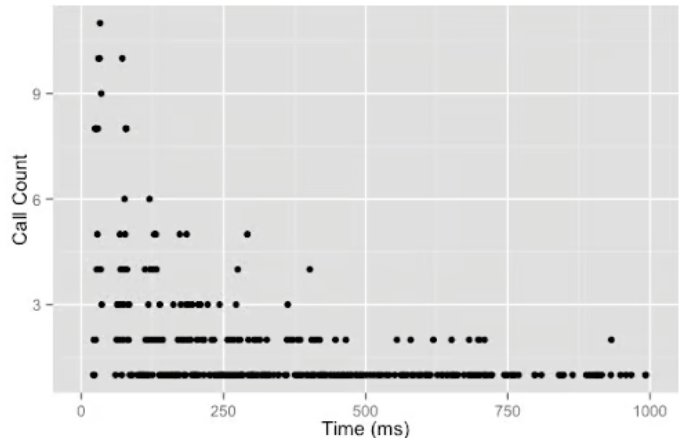
- Adding Jitter:
- Introduce randomness to retry intervals to prevent synchronized retries.
- Example:
- User 1 Retry 1: 100ms, Retry 2: 600ms.
- User 2 Retry 1: 300ms, Retry 2: 900ms.
- This spreads out retries, giving the system time to recover.
Request Queuing
- What It Does: Implements a queue to control access to shared resources.
- How It Works:
- Requests are placed in a queue and processed sequentially.
- Prevents simultaneous access to the resource.
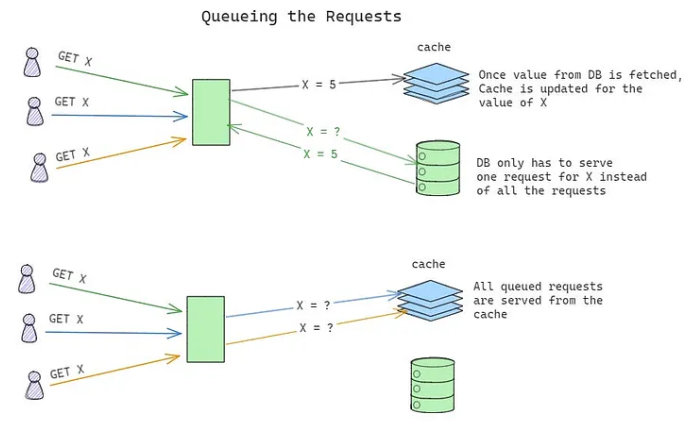
- Example: In a cache stampede scenario, only one request fetches data from the origin, while others wait for the cache to update.
Load Balancing
- What It Does: Distributes incoming requests across multiple servers.
- How It Works:
- Routes requests to healthy servers, reducing the load on any single server.
- Removes unhealthy servers from the pool.
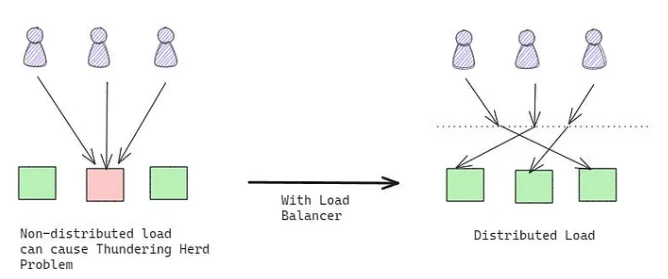
- Example: A load balancer routes requests to the least busy server in a cluster.
Caching
- Browser Caching: Stores resources locally on the user’s device to reduce server load.
- CDN Caching: Content Delivery Networks serve cached resources from edge locations.
- Application Caching:
- Use in-memory caches (e.g., Redis, Memcached) for quick data retrieval.
- Cache database query results or frequently accessed objects.
Precautions and Best Practices
Implement Buffer Workers
- Maintain idle workers to handle unexpected traffic spikes.
- This creates a cushion for sudden surges.
Regular Resource Monitoring
- Monitor system performance and identify trends to optimize resource allocation.
Optimize Autoscaling
- Configure autoscalers to respond quickly to spikes.
- Use predictive scaling based on historical traffic patterns.
Test For Edge Cases
- Simulate traffic surges and failure scenarios to identify vulnerabilities.
Conclusion
The Thundering Herd Problem is a critical challenge in distributed systems, but it can be mitigated with a combination of strategies like rate limiting, load shedding, exponential backoff with jitter, and caching. By understanding the root causes and implementing proactive solutions, organizations can ensure system stability and resilience, even during traffic surges.



