Vector Space (Similarity) Search

Vector space (Similarity) searching in the context of facial recognition systems.
In this article we will discuss the following:
- Vector
- Vector Space
- Use cases for Vector space models
- Importance of Vector Representation and the Distance function
- Vector Similarity search
- Using Indexes for Vector Similarity Search
Vectors
The standard definition of Vectors which all of us might remember from our Physics books is: “An object which has both magnitude and a direction” . But on running a Wikipedia search for Vectors you would see something like “In Mathematics and Physics, a Vector is an element of a vector space” .
Well, we are gonna push it a bit further for our readers and make this a little bit more boring and comprehensive. The definition of Vector space is “ In Mathematics, Physics and Engineering, A Vector space (Also called a linear space) is a set of objects called Vectors, which may be added together or multiplied (“Scaled”) by numbers called Scalars.

If all those complex definitions make your head spin, we’ll break them down for our mutual understanding and to get a basic idea of the subject we are discussing.
Vectors can be considered an ordered collection of elements, typically numbers which are meaningful to us in a given domain. For those with a computer science background, you can consider vectors as 1 dimensional arrays.
And a vector space is just a collection of vectors in an abstract “space”, with some boring mathematical properties (only one of which is relevant for us for now, namely distance).
Vector Representation
There are several different ways to use vectors in a model depending on the requirements. A general rule of thumb when considering how to represent an entity/data point as a vector is that the vector for a given entity should capture as much information contained in the entity as is possible in order for the vector (and the vector space in general) to be useful.
Let’s say we are working to classify some text. First, we’ll have to represent the words in a way that a computer (and our ML model) can work with them (in order to understand their relationship, and to infer something useful about a collection of words). The simplest way to represent these words would be to create a collection of unique words that occur across the text we’re working with, and use the index of a given word in that set as it’s representation, but that causes a whole host of issues due to the ordinal properties of natural numbers.
A word with index 42 would seem closer to a word with index 41 than it does to one with index 10, at least from the perspective of our model. Moreover, this representation doesn’t capture any information about the words and their collections (documents) at all.The next iteration might be to use one-hot encoded vectors (vectors with all zeros except the cell at index corresponding to a word being 1).
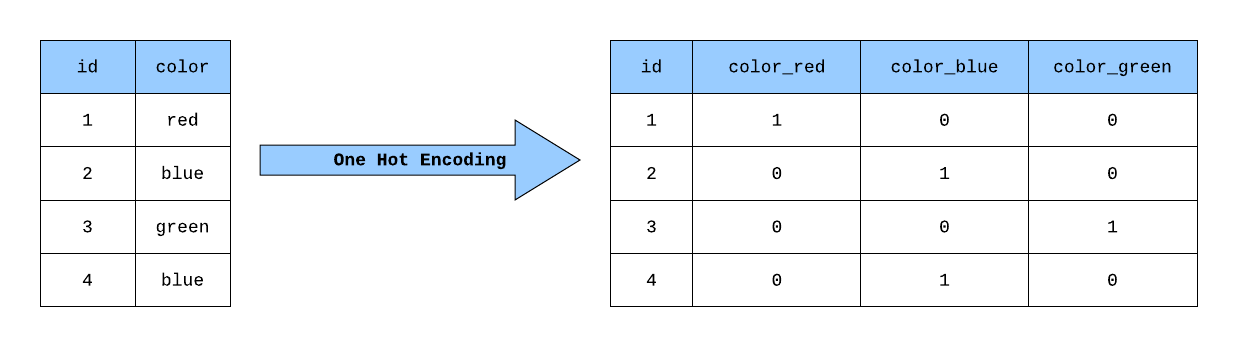
This would alleviate the distance problem a bit (as each word would just be one unit away from every other word), and would allow the model to work in higher dimensions (useful for reasons that I can’t explain here without turning this into an article about Machine Learning), but it’s still not a good representation. All the words are equi-distant from each other, and the size of the vectors is directly a function of the number of unique words in our document collection (so if we have 1000 unique words across 100 documents containing an average 100 words, we’ll be working with a 100 1000x100 matrices. And usually these quantities are much larger).
So we come to the Bag-of-Words approach, where we convert the text into fixed length vectors, and the cell with the index corresponding to a given word contains its frequency in said document. This is a very simple and naive vector representation for words as it does not capture any semantic information from our document, and only allows us to track or target words regardless of their context and meaning in this scenario, but it works quite well in practice.
There are better ways to represent the words as vectors (TF-IDF, word embeddings, Transformers etc), an explanation of which is beyond the scope of this article.
Distance
The concept of distance is quite important in order to make use of vectors and vector spaces. Ideally, our vector representation should be such that the distance between similar items is less than it is between dissimilar items (or we can assume that if we are fitting/training a statistical/ML model). This way, distance between different vectors in a vector space can be treated as an inverse measure of similarity. The smaller the distance between two vectors in a vector space, the more similar those two vectors are (or ought to be) and vice versa.
The choice of which distance function to use depends on the given problem, and the vector representation of your data.A simple application of distance as a (inverse) measure of similarity can be seen in algorithms like K-Nearest Neighbors, and K-Means.
K-Nearest Neighbors
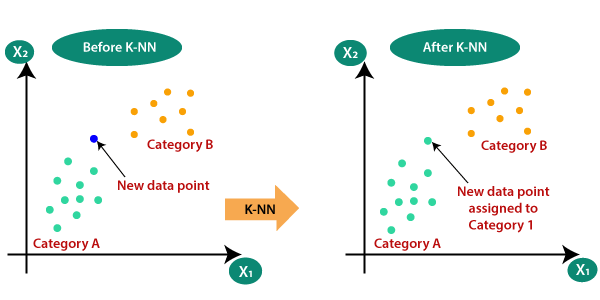
Let’s say we have some data, and we want to use that to infer something about the future data points, like what group/category do they belong to (Classification - Supervised Learning)
If our vector representation and choice of distance function is appropriate, we can be reasonably certain that the closer two vectors are in our vector space, the more similar they’ll be. Therefore, our unknown data point from the future will most likely belong to the same category as that of the (known) points nearest to it. So, we find out the K nearest points (the K Nearest Neighbors) of the data point/object/item/entity to classify, and use majority voting (or it's better variations like distance weighted majority voting) to assign a category/label to our new data point.
Vector Similarity Search
Running a similarity search using KNN method is computationally expensive. Meaning that as the size of the dataset or vector store increases, the efficiency of our similarity search would decrease. In order to increase efficiency, we can reduce the vector size by compression or using dimensionality reduction which could cause us to lose some information. Or, by reducing the size of the search space by using Indexing or Clustering via K-Means etc. This would lead to a trade off of accuracy for decreased time and space complexity.
Indexes for Vector Space Search:
There are various ways to index vectors for efficient searching, some of them are briefly mentioned below.
- Flat Index - In this method, the vectors are not clustered or modified, basically KNN.
- Locally Sensitive Hashing (LSH) - Vectors are grouped into buckets (buckets would become the new vector search space) using a hashing function that maximizes hash collision.
- Hierarchical Navigable Small World graphs - The main components are Nodes (vectors), Edges (distance to the nearest neighbor). The reasoning behind this method is that small numbers of hops will be required on average, to traverse the path between two given nodes. P.S This method is used at Facebook.
- Inverted File Index - Here we use Dirichlet tessellation for clustering.
Where not to Use Vector Similarity Search
If your similarity search problem can be solved by directly comparing the object properties, and the object properties are not high dimensional, and/or all of them are finite and categorical, you don’t need to convert them to vectors and perform the vector space search. Or,
- Why send a request to the backend to calculate 2+2 when you can do it client side?
- Why use a deep learning model to simulate AND logic operation?
- Finite/categorical properties – Simple Field Comparison
- Any place where a simpler approach would suffice.
Summary
- Vectors can be considered an ordered collection of elements, typically numbers which are meaningful to us in a given domain.For those with a computer science background, you can consider vectors as 1 dimensional arrays.
- A vector space is just a collection of vectors in an abstract “space”, with some boring mathematical properties (only one of which is relevant for us for now, namely distance).
- If your similarity search problem can be solved by directly comparing the object properties, and the object properties are not high dimensional, and/or all of them are finite and categorical, you don’t need to convert them to vectors and perform the vector space search.
- A general rule of thumb when considering how to represent an entity/data point as a vector is that the vector for a given entity should capture as much information contained in the entity as is possible in order for the vector (and the vector space in general) to be useful.
- The concept of distance is quite important in order to make use of vectors and vector spaces. Ideally, our vector representation should be such that the distance between similar items is less than it is between dissimilar items.
- A Vector Similarity search involves indexing data points as Vectors for efficient searching. Can be done by various methods such as Flat index, LSH, Hierarchical Navigable Small World graphs, Inverted File Index.
Did you think of any way Vector Similarity search could be used to solve a problem?



